Ordinary and Simple Kriging#
This tutorial will teach us how to perform spatial interpolation with Ordinary and Simple Kriging. We will compare Kriging behavior in relation to a different number of ranges, and finally check how number of neighbors changes the interpolation quality. Ordinary and Simple Kriging are the simplest form of Kriging, but they’re still powerful, thus you should always start from those methods and then move to more sophisticated techniques.
Prerequisites#
Domain:
semivariance and covariance functions
kriging (basics)
Package:
TheoreticalVariogramExperimentalVariogram
Programming:
Python basics
Table of contents#
Set semivariogram model (fit data into semivariogram).
Create Ordinary and Simple Kriging models.
Predict values at unknown locations and evaluate output.
1. Set semivariogram model (fit)#
[1]:
import geopandas as gpd
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pyinterpolate import (
build_experimental_variogram,
build_theoretical_variogram,
ordinary_kriging,
simple_kriging
)
[2]:
# Load DEM data
df = pd.read_csv(
'../data/dem.csv'
)
# Populate geometry column and set CRS
dem_geometry = gpd.points_from_xy(x=df['longitude'], y=df['latitude'], crs='epsg:4326')
dem = gpd.GeoDataFrame(df, geometry=dem_geometry)
# Transform crs to metric values
dem.to_crs(epsg=2180, inplace=True)
dem.plot(column='dem', cmap='gist_earth', alpha=0.6, vmin=0, legend=True);

In the beginning, we remove 90 % of our points from the dataset, and we will leave them as a test set to calculate interpolation error of Kriging models.
Note: probably you have realized, that we put much more records in test set than in classic machine learning. This simulates real-world problems where we have only few samples and we must deliver a large surface of predicted values.
[3]:
train = dem.sample(n=int(0.1*len(dem)))
test = dem.loc[~dem.index.isin(train.index)]
[4]:
len(train), len(test), len(dem) - (len(train) + len(test))
[4]:
(689, 6206, 0)
[5]:
train.plot(column='dem', cmap='gist_earth', alpha=0.6, vmin=0, legend=True)
train.head()
[5]:
| longitude | latitude | dem | geometry | |
|---|---|---|---|---|
| 1478 | 15.168636 | 52.628530 | 19.145895 | POINT (240802.993 536090.593) |
| 1229 | 15.158352 | 52.723126 | 56.446690 | POINT (240668.961 546640.642) |
| 3055 | 15.226381 | 52.715467 | 18.290354 | POINT (245214.816 545546.353) |
| 1970 | 15.185643 | 52.595825 | 46.901897 | POINT (241760.565 532394.821) |
| 3945 | 15.261187 | 52.681934 | 18.407000 | POINT (247370.181 541696.816) |
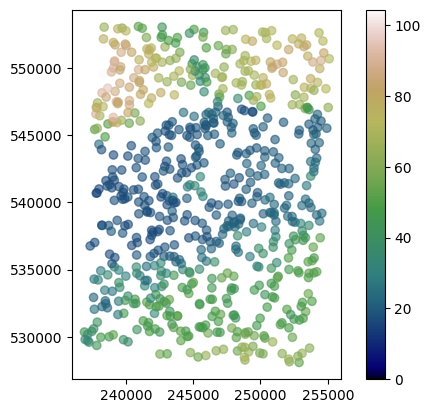
We have removed a subset of points from a dataset to be sure that Kriging is working. In this scenario, 90% of available points are removed, but in real-world cases, you will probably have even fewer points to perform estimations, down to the ~1% of known values.
We have two variables right now:
train: training set used for semivariogram model derivation,test: test set used for the model error calculation.
The worst idea is to take sample as k first values from the list. Let’s imagine we have a sorted list of Digital Elevation Model points. The western part of our measurements covers a mountain, and the eastern part is plain. When we use the part of the west for modeling and the east part for tests, we are going directly into a catastrophe! Points for each set are chosen randomly to avoid bias related to the geographical location, but we cannot be sure that the sampled points are not from
the neighborhood, thus in a fully controlled scenario we perform this experiment multiple times sampling dataset dozens or hundreds of times.
Having datasets, we can start modeling. Kriging requires fitted theoretical semivariogram.
[6]:
step_size = 500 # meters
max_range = 10000 # meters
exp_var = build_experimental_variogram(
values=train['dem'],
geometries=train['geometry'],
step_size=step_size,
max_range=max_range
)
[7]:
exp_var.plot();

[8]:
theo_var = build_theoretical_variogram(
experimental_variogram=exp_var,
models_group='linear'
)
[9]:
theo_var.plot()

[10]:
print(theo_var)
* Selected model: Linear model
* Nugget: 0.0
* Sill: 480.57557214875214
* Range: 8028.237650988341
* Spatial Dependency Strength is Undefined: nugget equal to 0, cannot estimate
* Mean Bias: None
* Mean RMSE: 25.496114727814966
* Error-lag weighting method: equal
+--------+--------------------+--------------------+---------------------+
| lag | theoretical | experimental | bias (real-yhat) |
+--------+--------------------+--------------------+---------------------+
| 500.0 | 29.930327989829088 | 16.982943545110665 | -12.947384444718423 |
| 1000.0 | 59.860655979658176 | 30.336797059220284 | -29.523858920437892 |
| 1500.0 | 89.79098396948727 | 55.19369693532188 | -34.59728703416539 |
| 2000.0 | 119.72131195931635 | 72.64214325577524 | -47.079168703541114 |
| 2500.0 | 149.65163994914545 | 119.83419152308294 | -29.817448426062512 |
| 3000.0 | 179.58196793897454 | 127.38055541167519 | -52.201412527299354 |
| 3500.0 | 209.51229592880364 | 173.80396800141062 | -35.708327927393015 |
| 4000.0 | 239.4426239186327 | 221.17530533500022 | -18.267318583632488 |
| 4500.0 | 269.3729519084618 | 244.3961592666817 | -24.976792641780094 |
| 5000.0 | 299.3032798982909 | 279.82078294996256 | -19.482496948328333 |
| 5500.0 | 329.23360788812 | 332.5369149543105 | 3.3033070661904844 |
| 6000.0 | 359.1639358779491 | 367.62601681181036 | 8.462080933861273 |
| 6500.0 | 389.0942638677782 | 397.55117274410134 | 8.456908876323155 |
| 7000.0 | 419.0245918576073 | 432.9732345205596 | 13.948642662952295 |
| 7500.0 | 448.9549198474363 | 451.60459167886455 | 2.649671831428236 |
| 8000.0 | 478.8852478372654 | 462.7533281080885 | -16.1319197291769 |
| 8500.0 | 480.57557214875214 | 488.04251358205227 | 7.466941433300121 |
| 9000.0 | 480.57557214875214 | 489.5822318182907 | 9.006659669538578 |
| 9500.0 | 480.57557214875214 | 510.8951955564648 | 30.31962340771264 |
+--------+--------------------+--------------------+---------------------+
2. Create Ordinary and Simple Kriging models#
This is the essential step of our tutorial. We’ve fit semivariances to the model that is utilized by Kriging algorithm. Knowing this model, we can interpolate values in empty locations.
We will predict a known and arbitrary point in the first run. It is not a real prediction, but test of Kriging. When we perform Kriging, we should get the same exact values as in training data because Kriging is an unbiased linear estimator. Then, we will interpolate values at unknown locations given in the test set, and calculate the Root Mean Squared Error (RMSE) between those predicted and real values.
Functions ordinary_kriging() and simple_kriging() are similar, there is only one parameter that is different - process_mean, and it is passed only to the simple_kriging() function. Kriging parameters are:
theoretical_model: fittedTheoreticalVariogrammodelknown_values: observed values at known locationsknown_geometries: coordinates of known locationsunknown_locations: locations where you want to interpolate a missing value (or a single location)neighbors_range: optional parameter, the maximum distance where we search for point neighbors. If you don’t provide it then it is equal to the range of theoretical variogram modelno_neighbors: number of the closest neighbors used for interpolation, by default it is set to 4, but for datasets with many point samples it is recommended to use more neighborsmax_tick: If searching for neighbors in a specific direction how large should be tolerance for increasing the search angle (how many degrees more)use_all_neighbors_in_range: boolean parameter.True: if the number of neighbors within theneighbors_rangeis greater than theno_neighbors, then take all of them for modeling. Otherwise, take only n-closest neighborsallow_approx_solutions: Allows the approximation of kriging weights based on the OLS algorithm. This is by default set toFalse, and parameter is useful for debugging purposes. Do not ignore errors coming from the Kriging system because usually those errors inform you about data quality (duplicated coordinates, clusters, etc.)process_mean: The mean value of a process over a study area. Should be known before processing. That’s why Simple Kriging has a limited number of applications. You must have multiple samples and well-known area to know this parameter.
We use only the first four parameters and process_mean when we run Simple Kriging. Let’s start! The first step is an interpolation of the value known by our model.
[11]:
# Select one known value
known_value = train.sample()
known_value
[11]:
| longitude | latitude | dem | geometry | |
|---|---|---|---|---|
| 6260 | 15.34741 | 52.732855 | 48.885471 | POINT (253481.516 547057.061) |
[12]:
# Predict with Ordinary Kriging
unknown_location = known_value.geometry.iloc[0]
print(unknown_location)
POINT (253481.51620009867 547057.0611242605)
[13]:
ok_interpolation = ordinary_kriging(
theoretical_model=theo_var,
known_values=train['dem'],
known_geometries=train['geometry'],
unknown_locations=unknown_location,
progress_bar=False
)
print(ok_interpolation)
[[4.88854713e+01 0.00000000e+00 2.53481516e+05 5.47057061e+05]]
[14]:
print(known_value['dem'] - ok_interpolation[0][0])
6260 0.0
Name: dem, dtype: float64
The first value is our prediction is precisely the same as the input in the training set! So far, the algorithm has worked well. The second value is prediction variance error, equal, or really close to zero - as it should be.
Simple Kriging differs from Ordinary Kriging, and we must set the process mean to retrieve valid results. It is rarely the case. That’s why Ordinary Kriging is the first choice for many applications. We know the global mean because we have the whole dataset, but in the real-world scenario, we cannot divide the set into training and test sets and then get the mean from the entire dataset - it is an information leak from the test set into a model!
[15]:
sk_interpolation = simple_kriging(
theoretical_model=theo_var,
known_values=train['dem'],
known_geometries=train['geometry'],
unknown_locations=unknown_location,
process_mean=np.mean(df['dem'])
)
print(sk_interpolation)
100%|██████████| 1/1 [00:00<00:00, 614.73it/s]
[[4.88854713e+01 0.00000000e+00 2.53481516e+05 5.47057061e+05]]
The Simple Kriging algorithm returns the same output as the Ordinary Kriging: [prediction, error variance, pt x, pt y]. Simple Kriging has returned the same value as the actual value fed to the algorithm.
3. Predict values at unknown locations and evaluate output#
In this part of the tutorial we interpolate values at missing locations. Kriging does it (usually) better than other simple techniques like filling missing data with the averages or inverse distance weighting. Interpolation quality is driven mostly by a good semivariogram model, but we can make better predictions when we scan more neighbors around the missing location. We will test this assumption in the next step, validating output with test dataset, and calculating the root mean squared error of prediction.
We will perform those tests only for ordinary kriging, dividing dataset multiple times to get distribution of errors for each number of neighbors.
[16]:
from tqdm import tqdm
neighbors_number = [4, 8, 16, 32, 64, 128, 256, 512]
number_of_trials = 10
outputs = []
for _ in range(number_of_trials):
for nn in tqdm(neighbors_number):
# Divide dataset into train and test set
train = dem.sample(n=int(0.1*len(dem)))
test = dem.loc[~dem.index.isin(train.index)]
# Take sample from test, we don't need a whole dataset
test_sample = test.sample(n=100)
# Fit semivariogram model
exp_var = build_experimental_variogram(
values=train['dem'],
geometries=train['geometry'],
step_size=step_size,
max_range=max_range
)
theo_var = build_theoretical_variogram(
experimental_variogram=exp_var,
models_group='linear'
)
# Predict new values
yhats = ordinary_kriging(
theoretical_model=theo_var,
known_values=train['dem'],
known_geometries=train['geometry'],
unknown_locations=test_sample['geometry'],
no_neighbors=nn,
use_all_neighbors_in_range=False,
progress_bar=False
)
yhats = yhats[:, 0]
avg_rmse = np.sqrt(np.mean((test_sample['dem'] - yhats)**2))
outputs.append([avg_rmse, nn])
100%|██████████| 8/8 [00:02<00:00, 2.74it/s]
100%|██████████| 8/8 [00:02<00:00, 3.60it/s]
100%|██████████| 8/8 [00:02<00:00, 3.54it/s]
100%|██████████| 8/8 [00:02<00:00, 3.55it/s]
100%|██████████| 8/8 [00:02<00:00, 3.37it/s]
100%|██████████| 8/8 [00:02<00:00, 3.34it/s]
100%|██████████| 8/8 [00:02<00:00, 3.43it/s]
100%|██████████| 8/8 [00:02<00:00, 3.36it/s]
100%|██████████| 8/8 [00:02<00:00, 3.25it/s]
100%|██████████| 8/8 [00:02<00:00, 3.36it/s]
[17]:
# create dataframe from results
df = pd.DataFrame(outputs, columns=['rmse', 'nn'])
df.head()
[17]:
| rmse | nn | |
|---|---|---|
| 0 | 3.572057 | 4 |
| 1 | 4.489833 | 8 |
| 2 | 4.091741 | 16 |
| 3 | 5.458568 | 32 |
| 4 | 4.077269 | 64 |
[18]:
# First plot average rmse per number of neighbors
plt.figure()
plt.plot(df.groupby('nn')['rmse'].mean())
plt.xlabel('Number of neighbors')
plt.ylabel('RMSE')
plt.show()
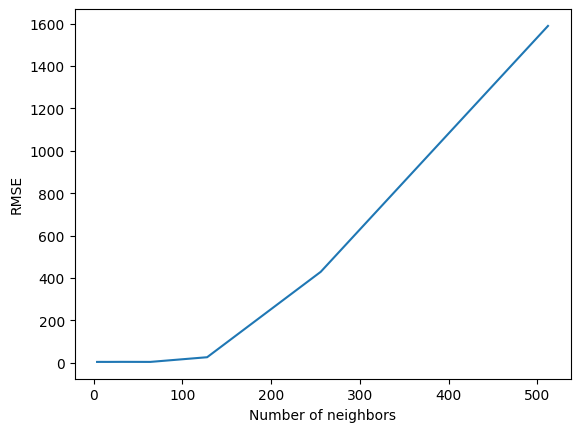
As we see, there could be too many neighbors - interpolations become wildly inaccurate. We can check general statistics for each number of neighbors using .describe() method on transformed dataframe:
[19]:
# First, set number of neighbors as a column
transformed = df.pivot(columns='nn', values='rmse')
transformed.head()
[19]:
| nn | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
|---|---|---|---|---|---|---|---|---|
| 0 | 3.572057 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | NaN | 4.489833 | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | NaN | NaN | 4.091741 | NaN | NaN | NaN | NaN | NaN |
| 3 | NaN | NaN | NaN | 5.458568 | NaN | NaN | NaN | NaN |
| 4 | NaN | NaN | NaN | NaN | 4.077269 | NaN | NaN | NaN |
[20]:
transformed.describe()
[20]:
| nn | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
|---|---|---|---|---|---|---|---|---|
| count | 10.000000 | 10.000000 | 10.000000 | 10.000000 | 10.000000 | 10.000000 | 10.000000 | 10.000000 |
| mean | 4.424563 | 4.589075 | 4.531294 | 4.754989 | 4.510437 | 26.591935 | 429.343974 | 1588.650863 |
| std | 0.721704 | 0.745411 | 0.671426 | 1.025088 | 0.469793 | 45.112219 | 456.209873 | 2928.686785 |
| min | 3.572057 | 3.333597 | 3.688744 | 3.262639 | 3.769000 | 4.388957 | 45.168559 | 183.274077 |
| 25% | 3.992381 | 4.271690 | 3.909511 | 4.317161 | 4.145270 | 5.895184 | 83.092058 | 243.304685 |
| 50% | 4.195704 | 4.547581 | 4.599459 | 4.672608 | 4.537990 | 7.752335 | 272.913118 | 359.240210 |
| 75% | 4.744351 | 5.106922 | 5.043499 | 4.879660 | 4.809733 | 17.771979 | 685.394778 | 691.069539 |
| max | 5.829943 | 5.718141 | 5.551242 | 7.140792 | 5.207114 | 149.477744 | 1406.556887 | 9413.566202 |
In general, too much neighbors might worsen the results; we are assuming, that the closest neighbors are the most important, and introducing more distant neighbors may amplify the noise in the model response.
The best idea is to look into semivariogram and limit range as much as you can. Then you will be sure, that only the closest neighbors are taken into account.
Changelog#
Date |
Changes |
Author |
|---|---|---|
2025-11-07 |
Used values and geometries parameters instead of ds in the experimental variogram initialization, and known_values and known_geometries for kriging process (instead of known_locations parameter) |
@SimonMolinsky (Szymon Moliński) |
2025-04-30 |
Tutorial has been adapted to the 1.0 release |
@SimonMolinsky (Szymon Moliński) |
2025-07-10 |
Changed behavior of |
@SimonMolinsky (Szymon Moliński) |