Poisson Kriging Centroid-based approach#
Before starting this tutorial, be sure that you have understood concepts in of ordinary kriging and semivariogram regularization.
The Poisson Kriging technique is used to model spatial count data. We analyze a particular case where values are counted over blocks, and those polygons have irregular shapes and sizes. We will predict the breast cancer rates in the Northeastern counties of the U.S. We use U.S. Census 2010 data to create point support for blocks.
Even if our areal data has polygons with irregular shapes and sizes, we can assume that each region may be represented by its centroid. This is a huge simplification; we can do it at our own risk. However, there are cases when we can use this method instead of the Area-to-Area Kriging. Those cases are:
we need to perform fast and scalable calculations
blocks are similar in shapes and sizes (e.g. blocks are hexagons, or rectangular shape)
Centroid-based Poisson Kriging is much faster than Area-to-Area or Area-to-Point Poisson Kriging, and for some applications, it may be the desired property.
Prerequisites#
Domain:
kriging
Poisson kriging and Poisson distribution
rates
Package:
Deconvolution()ordinary_kriging()TheoreticalVariogram()
Programming:
Python basics
pandasbasics
Table of contents#
Prepare data
Load regularized semivariogram model
Prepare data for Poisson Kriging
Filtering areas
Evaluate
1. Prepare data#
[1]:
import geopandas as gpd
import numpy as np
import pandas as pd
from tqdm import tqdm
from pyinterpolate import TheoreticalVariogram, Blocks, PointSupport, centroid_poisson_kriging
[2]:
DATASET = '../data/blocks/cancer_data.gpkg'
OUTPUT = '../data/regularized_variogram.json'
POLYGON_LAYER = 'areas'
POPULATION_LAYER = 'points'
POP10 = 'POP10'
GEOMETRY_COL = 'geometry'
POLYGON_ID = 'FIPS'
POLYGON_VALUE = 'rate'
[3]:
blocks = Blocks(
ds=gpd.read_file(DATASET, layer=POLYGON_LAYER),
value_column_name=POLYGON_VALUE,
geometry_column_name=GEOMETRY_COL,
index_column_name=POLYGON_ID
)
[4]:
point_support = PointSupport(
points=gpd.read_file(DATASET, layer=POPULATION_LAYER),
blocks=blocks,
points_value_column=POP10,
points_geometry_column=GEOMETRY_COL,
verbose=True
)
[5]:
blocks.ds.plot(column=blocks.value_column_name,
cmap='Spectral_r',
legend=True,
figsize=(12, 8))
[5]:
<Axes: >
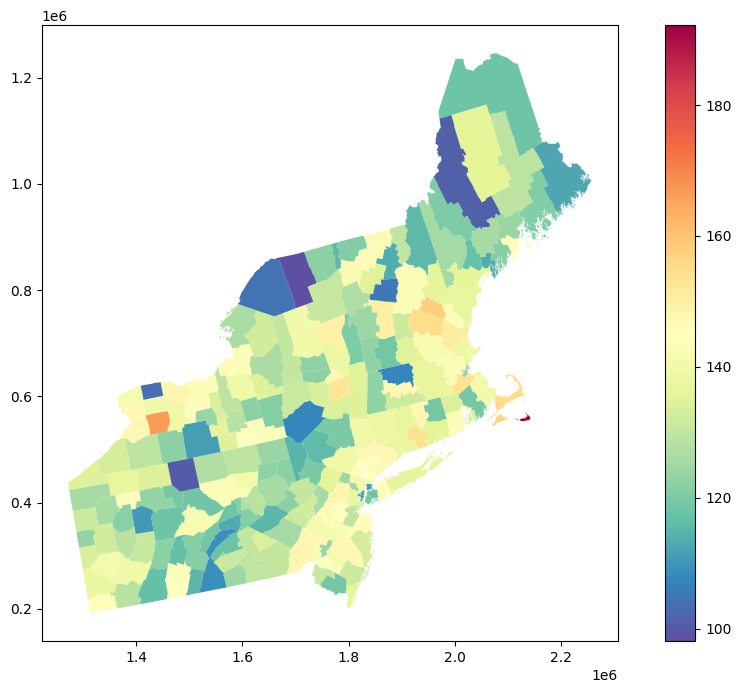
Clarification: It is always a good idea to look into the spatial patterns in dataset and to visually check if our data do not have any NaN values. We use the geopandas GeoDataFrame.plot() function with a color map that diverges regions based on the cancer incidence rates. The output map is not ideal, and it has a few unreliable results, for example:
In counties with a small population, where the ratio number of cases to population size is high even if the number of cases is low,
Counties that are very big and sparsely populated may draw more of our attention than densely populated counties,
Transitions of colors (rates) between counties may be too abrupt, even if we know that neighboring counties should have closer results.
We can overcome those problems using Centroid-based Poisson Kriging for filtering. But we must be aware that this method introduces a bias: each polygon falls into its centroid, but polygons’ shapes and sizes differ, so centroid representation erases spatial patterns.
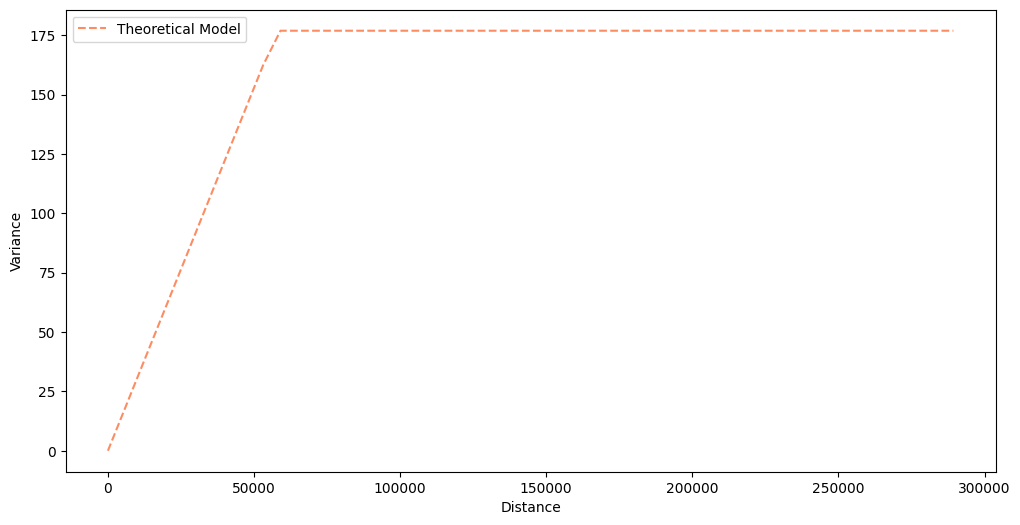
2. Load regularized semivariogram model#
We load a regularized semivariogram from the tutorial about Semivariogram Regularization. You can always perform semivariogram regularization along with the Poisson Kriging, but it is a very long process, and it is more convenient to separate those two steps.
[6]:
semivariogram = TheoreticalVariogram()
[7]:
semivariogram.from_json(OUTPUT)
[8]:
semivariogram.plot(experimental=False)
3. Prepare data for Poisson Kriging#
We simply select random blocks values from blocks data and try to predict those values using Poisson Kriging.
[9]:
sample_ids = blocks.ds.sample(20)['FIPS'].to_numpy()
[10]:
sample_ids
[10]:
array([42039, 36113, 34007, 42103, 36003, 42087, 36069, 36037, 36073,
42037, 25021, 50015, 34023, 36091, 36043, 42099, 36047, 33015,
36067, 36061])
4. Filtering areas#
You may start to work with predictions with a fitted semivariogram model. Centroid-based Poisson Kriging takes five arguments during the run:
semivariogram_model: fitted semivariogram model
point_support: point support data
unknown_block_index: id of the interpolated block (
point_supportmust have this block’s point support coordinates and values)neighbors_range: how wide is neighbors search area, by default it is
semivariogram_modelrangenumber_of_neighbors: how many neighbors are used for the interpolation
The algorithm in the cell below iteratively picks one area from the test set and performs prediction. Then, forecast bias, the difference between actual and predicted value, is calculated. Forecast Bias clarifies if our algorithm predictions are too low or too high (under- or overestimation). The following parameter is the Root Mean Squared Error. This measure tells us more about outliers and huge differences between predictions and actual values. We will see it in the last part of the tutorial.
[11]:
preds = []
for b_id in tqdm(sample_ids):
pred = centroid_poisson_kriging(
semivariogram_model=semivariogram,
point_support=point_support,
unknown_block_index=b_id,
neighbors_range=semivariogram.rang*2,
number_of_neighbors=8,
raise_when_negative_error=False,
allow_lsa=False
)
preds.append(pred)
100%|██████████| 20/20 [00:00<00:00, 100.44it/s]
[12]:
results = pd.DataFrame(preds)
[13]:
results = results.merge(blocks.ds, left_on='block_id', right_on='FIPS')
[14]:
results.head()
[14]:
| block_id | zhat | sig | FIPS | rate | geometry | representative_points | lon | lat | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 42039 | 131.741785 | 3.457992 | 42039 | 125.8 | MULTIPOLYGON (((1349111.317 410802.404, 134910... | POINT (1310701.148 411516.603) | 1.310701e+06 | 411516.603004 |
| 1 | 36113 | 130.425060 | NaN | 36113 | 149.2 | MULTIPOLYGON (((1789030.054 694720.858, 178903... | POINT (1768071.525 720868.227) | 1.768072e+06 | 720868.226866 |
| 2 | 34007 | 137.319410 | 8.996138 | 34007 | 141.0 | MULTIPOLYGON (((1762465.616 298408.678, 176227... | POINT (1776210.635 295268.618) | 1.776211e+06 | 295268.617923 |
| 3 | 42103 | 126.044354 | 5.025477 | 42103 | 119.6 | MULTIPOLYGON (((1708426.29 449014.359, 1708410... | POINT (1731431.566 458219.332) | 1.731432e+06 | 458219.332179 |
| 4 | 36003 | 131.443314 | NaN | 36003 | 122.2 | POLYGON ((1439270.105 529664.083, 1439501.505 ... | POINT (1467596.975 505510.96) | 1.467597e+06 | 505510.960112 |
5. Evaluate#
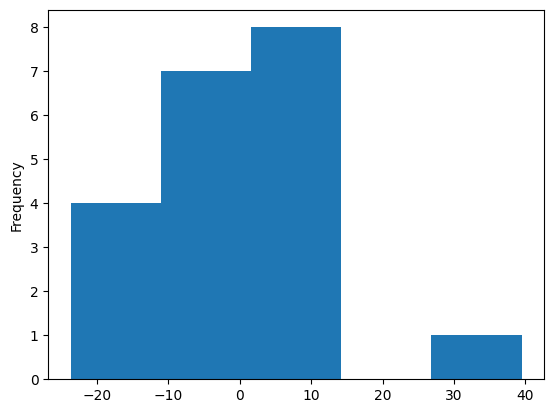
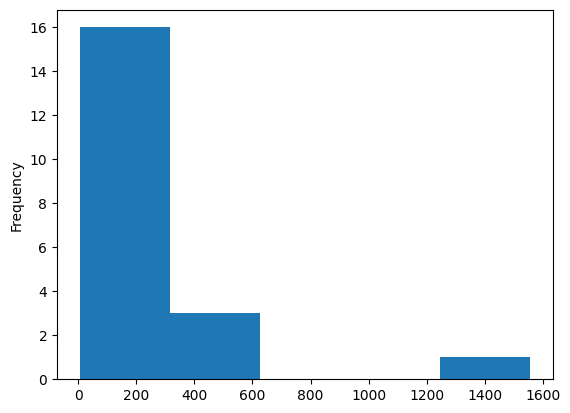
The analysis of errors is the last analysis step. We plot two histograms: forecast bias and squared error then we calculate the base statistics of a dataset.
[15]:
results['forecast_bias'] = results['zhat'] - results['rate']
results['squared_error'] = (results['rate'] - results['zhat'])**2
[16]:
results['forecast_bias'].plot(kind='hist', bins=5)
[16]:
<Axes: ylabel='Frequency'>
[17]:
results['squared_error'].plot(kind='hist', bins=5)
[17]:
<Axes: ylabel='Frequency'>
[18]:
results[['zhat', 'rate', 'forecast_bias', 'squared_error']].describe()
[18]:
| zhat | rate | forecast_bias | squared_error | |
|---|---|---|---|---|
| count | 20.000000 | 20.000000 | 20.000000 | 20.000000 |
| mean | 131.574586 | 132.880000 | -1.305414 | 185.804660 |
| std | 6.574559 | 13.410271 | 13.920850 | 356.853735 |
| min | 120.601986 | 103.400000 | -23.659756 | 4.407567 |
| 25% | 127.733954 | 121.550000 | -8.677488 | 12.200951 |
| 50% | 131.640182 | 134.200000 | -2.666852 | 56.582626 |
| 75% | 135.717496 | 141.675000 | 6.067428 | 153.072548 |
| max | 142.869604 | 153.200000 | 39.469604 | 1557.849657 |
[19]:
rmse = np.sqrt(np.mean(results['squared_error']))
print(rmse)
13.631018290285816
Clarification: Analysis of Forecast Bias and Root Mean Squared Error. Their distribution and basic properties are describing model performance. However, consider that the table above is a single test case (realization) and can be misleading. The good idea is to repeat the test dozens of times with a different training/test set division each time. After this, we average results from multiple tests and get insight into our model’s behavior.
negative forecast bias: model underestimates predictions
positive forecast bias: model overestimates predictions
forecast bias close to 0: model is (probably) accurate
root mean squared error: accuracy measure, large rmse means that model performs poorly or we have many outliers
Note 1: Those results are not decisive. Our sample has been selected randomly, and there is a chance that it is not a spatially representative sample! (E.g., areas only from one region). The good idea is to repeat the experiment multiple times with other samples and average results to determine how well the model performs.
Note 2: If we analyze errors’ statistics, we should consider not only error’s mean value. Let’s look at different pieces of information:
Histograms clearly show us how dispersed and grouped errors are, and most importantly, we directly see the worst predictions and how many of them are generated by our model.
What is plotted on a histogram is described by statistics. We may check the max and the min error, but the true power comes when we analyze quartiles and standard deviation.
The standard deviation is a good measurement of our model’s variance; lower standard deviation of errors, the better.
Sometimes, we must look into quartiles. A very high mean but relatively low median (or even the 3rd quartile) indicates that we have only a few wrong predictions (that could be interesting, because it means that few locations are heavily under- or over-estimated).
Changelog#
Date |
Changes |
Author |
|---|---|---|
2025-05-28 |
Tutorial has been adapted to the 1.0 release |
@SimonMolinsky (Szymon Moliński) |
[ ]: